Kubernetes Scheduler
Kubernetes Scheduler 基本使用概念
Scheduler Workflow
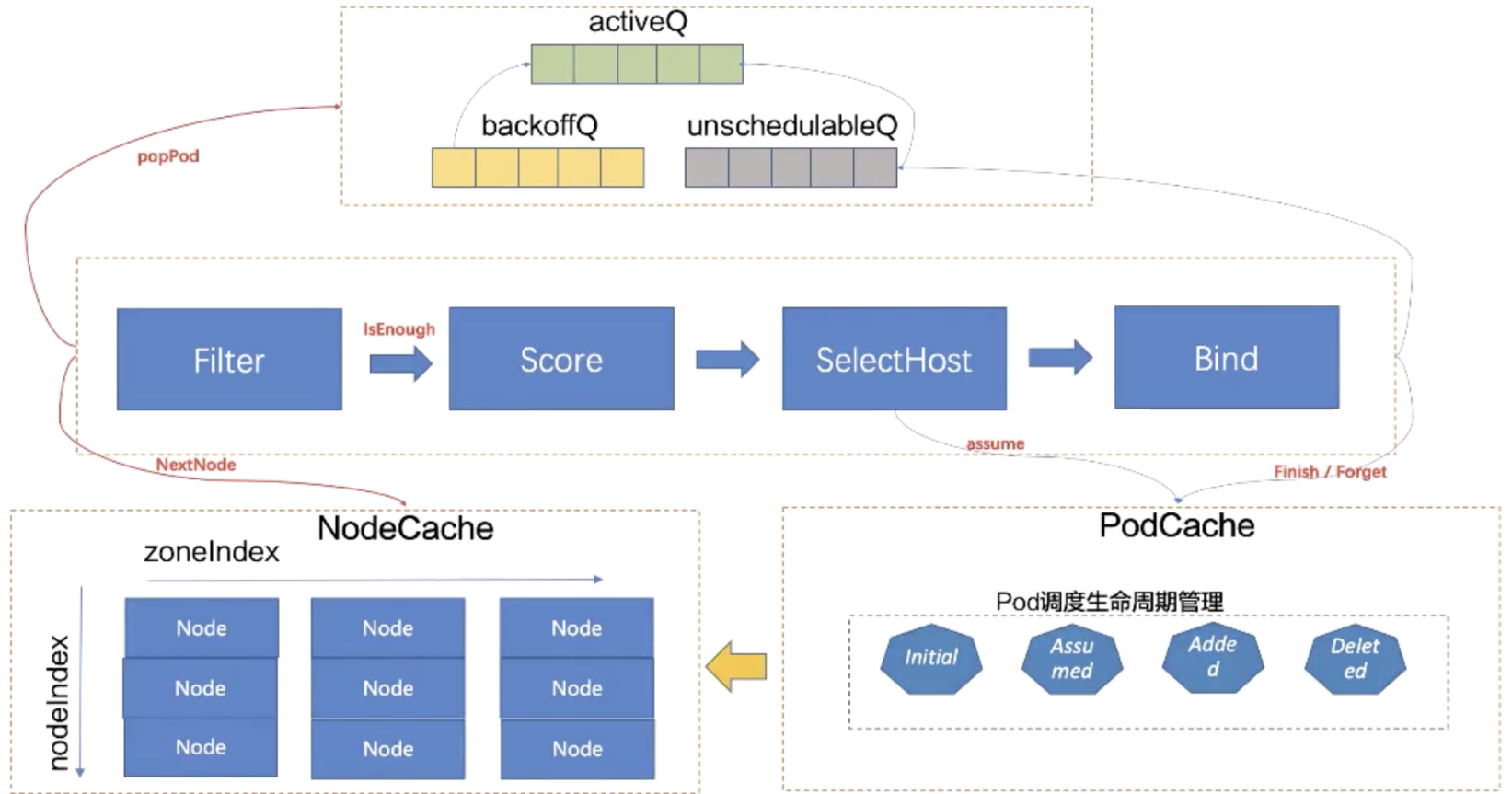
Scheduler WorkFlow定义了Scheduler Cycle和Binding Cycle,在Scheduler Cycle中有串行Filter 和Score两个阶段,Bind是异步并行阶段。
Scheduler FrameWork
Scheduler FrameWork是通过在Scheduler Cycle中通过预留扩展点来进行扩展调度流程,FrameWork预留了多个扩展点:
QueueSortFunc() LessFunc:Pod从队列中获取的优先级PreFilter: 在过滤之前执行Filter: 执行过滤函数PostFilter: 执行抢占PreScore:执行`Score之前执行Score: 执行Node打分PreBind: 执行Binding之前Bind: 执行Binding动作PostBind:执行Binding之后
自定义Schedlue可以通过直接实现Scheduler FrameWork中暴露的接口,然后在启动过程中进行Plugin注册即可。
func main() {
rand.Seed(time.Now().UTC().UnixNano())
logs.InitLogs()
defer logs.FlushLogs()
cmd := app.NewSchedulerCommand(
app.WithPlugin(sample.Name, sample.New),
)
if err := cmd.Execute(); err != nil {
_, _ = fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
Scheduler Plugin
如下的Scheduler Plugin是kube-scheduler里面内嵌的插件,涵盖了WorkFlow里面的所有流程。
Sort(排序)
1.PrioritySort
PrioritySort优先队列是进行Pod在入队时的排序函数,按找Pod的优先级进行排序,通过读取pod.Spec.Priority字段值进行排序,如果未设置Pod的优先级则按照添加到队列的时间先后进行排序。
p1 := pod1.Spec.Priority != nil ? *pod1.Spec.Priority : 0
p2 := pod2.Spec.Priority != nil ? *pod2.Spec.Priority : 0
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
Filter(预选)
1. InterPodAffinity
InterPodAffinity 检查Pod的亲和性是否满足,实现了PreFilterPlugin和FilterPlugin两个插件;
2. NodeAffinity
NodeAffinity是Node亲和性的过滤,通过pod.Spec.Affinity.NodeAffinity 是否配置Node亲和性和Node进行Match动作。
3.NodeName
NodeName用于在对pod.Spec.NodeName字段值的判断,判断是否是当前的Node,如果指定了pod.Spec.NodeName并且不是当前的节点,则返回UnschedulableAndUnresolvable状态。
4.NodePorts
NodePorts用于检查要启用的端口是否已经在Node上使用过,如果使用过则返回Unschedulable状态。
5.NodeResourcesFit
NodeResourcesFit 检查节点是否有足够的资源,如:cpu、memory、gpu等,通过那取max_resource(sum_pod, any_init_container)和node可分配的资源来判断节点是否资源足够。如果有任一资源不够,此节点则会返回资源不足被过滤。
6.NodeUnschedulable
NodeUnschedulable 插件过滤设置node.Spec.Unschedulable=true的节点,但是如果Pod设置了容忍Unschedulable的污点则不过滤。
7.NodeVolumeLimits
NodeVolumeLimits是一个节点检查volume容量的插件; 校验PVC指定的Provision在CSI plugin或非CSI Plugin(后三个)上报的单机最大挂盘数(存储插件提供方一般对每个节点的单机最大挂载磁盘数是有限制的)
8.PodTopologySpread
PodTopologySpread 是用于检查Pod的拓扑逻辑是否满足条件,
9.TaintToleration
TaintToleration是一个污点容忍度的插件,用于检查Pod是否能容忍次污点。Taint污点是Node上的标签,Toleration容忍度是Pod上的功能,一个容忍度和一个污点相“匹配”是指它们有一样的key和value。
10.VolumeBinding
VolumeBinding检查Pod挂载的PVC,如果其对应SC(StorageClass)的VolumeBindingMode是Immediate模式,该PVC必须已经是bound,否则需要返回UnschedulableAndUnresolvable。
11.VolumeRestrictions
VolumeRestrictions 检查挂载该Node上的卷是否满足存储提供者的要求
Score(优选)
1.ImageLocality
ImageLocality是一个打分插件,对于调度Pod的镜像已经存在Node上给评分。已经存在的镜像并且镜像越大的分越高;(逻辑就是越大的镜像如果被重新拉取需要花费更多的时间,但是小的镜像拉起来就快,所以镜像存在并且越大的分越高就是这个逻辑);如果一个节点上的镜像总大小< 23Mb则node会被打0分;如果一个节点上的镜像总大于1G * 容器数则会被打1分。
2.InterPodAffinity
InterPodAffinity在Pod亲和性之间计算亲和性的的分值。
3.NodeAffinity
NodeAffinity是通过节点的亲和性来进行节点打分的,PreScore 主要逻辑是从pod.Spec.Affinity.NodeAffinity.PreferredDuringSchedulingIgnoredDuringExecution字段中获取首选节点亲和配置,主要的是配置的weight字段值,在通过Label匹配过程中,发现Node.Meta.Label是匹配matchExpressions中的字段则score += weight,这样这个节点的优先级就提高了。
4.NodeResourcesBalancedAllocation
NodeResourcesBalancedAllocation节点资源均衡插件,是一个通过cpu和memory容量分数之间的差异,根据他们的优先级进行排名;对于资源使用率均衡的节点分值更高。
# ResourceSpec[{"name":"cpu","Weight":1},{"name":"memory","Weight":1}]
std = Σ((fraction(i)-mean)^2)/len(resources)
# std计算取决于需要均衡几种资源,如果只有cpu和memory
std=Abs( (cpuRequest1/cpuAllocable1 - memoryRequest1/memoryAllocable1) / 2 )
# node打分则由如下计算
score = (1 - std) * MaxNodeScore(100)
5.NodeResourcesFit
NodeResourcesFit打分已经配置的策略进行,有如下三种:
LeastAllocated: 优先分配资源最少的节点;就是资源堆叠MostAllocated: 优先分配资源最多的节点;就是资源打散RequestedToCapacityRatio: 可以自定义函数,对资源容量进行打分。
LeastAllocated计算节点分值逻辑:(cpu((capacity-requested)*MaxNodeScore*cpuWeight/capacity) + memory((capacity-requested)*MaxNodeScore*memoryWeight/capacity) + ...)/weightSum
MostAllocated 计算节点分值逻辑:(cpu(MaxNodeScore * sum(requested) / capacity) + memory(MaxNodeScore * sum(requested) / capacity) + ...) / weightSum
capacity是allocable
6.PodTopologySpread
PodTopologySpread权重为2
7.SelectorSpread
SelectorSpread是一个计算选择器传播优先级的打分插件;
8.TaintToleration
TaintToleration计算无法容忍污点的一个插件,用于给Pod 无法容忍污点打分,每一个无法容忍则+1,最后得到的就是Node的分。
Binding(绑定)
1. DefaultBind
DefaultBind是通过使用k8s client绑定Pod到Node。绑定流程是先创建一个Binding类型对象,通过设置Target字段值,来记录绑定对象的目标对象。
# Binding是将一个对象与另一个对象联系起来
type Binding struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Target ObjectReference `json:"target" protobuf:"bytes,2,opt,name=target"`
}
binding := &v1.Binding{
ObjectMeta: metav1.ObjectMeta{Namespace: p.Namespace, Name: p.Name, UID: p.UID},
Target: v1.ObjectReference{Kind: "Node", Name: nodeName},
}
创建Binding对象之后,通过Pods的Bind方法就可以进行结果绑定。最终是创建Pod的绑定。
POST /api/v1/namespaces/{namespace}/pods/{name}/binding
namespace: pod namespace
name: binding 名字
body: Binding对象结构体
选中的节点在和待调度Pod进行Bind的时候,有可能会Bind失败,此时需要做回退,把Pod的Assumed状态退回Initial,从Node里面把Pod数据账本擦除掉,会把Pod重新丢回到unschedulableQ队列里面。在unschedulableQ里,如果一个Pod一分钟没调度过,就会重新回到activeQ。它的轮询周期是30s。
调度失败的Pod会放到backoffQ,在backoffQ里等待的时间会比在unschedulableQ里更短,backoffQ里的降级策略是2的指数次幂降级。假设重试第一次为1s,那第二次就是2s,第三次就是4s,但最大到10s。
2.VolumeBinding
VolumeBinding是PreBinding作为Binding之前检查的Volume是否绑定到Node上面,
Preemption(抢占)
1.DefaultPreemption
DefaultPreemption是一个PostFilter插件,实现了默认抢占逻辑;当高优先级的Pod没有找到合适的Node时,会执行Preempt抢占算法,抢占的流程。
- 一个
Pod进入抢占的时候,首先会判断Pod是否拥有抢占的资格,有可能上次已经抢占过一次。 - 如果符合抢占资格,会先对所有的节点进行一次过滤,过滤出符合这次抢占要求的节点。然后
- 模拟一次调度,把优先级低的
Pod先移除出去,再尝试能否把待抢占的Pod放置到此节点上。然后通过这个过程从过滤剩下的节点中选出一批节点进行抢占。 ProcessPreemptionWithExtenders是一个扩展的钩子,用户可以在这里加一些自己抢占节点的策略。如果没有扩展的钩子,这里面不做任何动作。PickOneNodeForPreemption,从上面选出的节点里挑选出最合适的一个节点,策略包括:- 优先选择打破
PDB最少的节点; - 其次选择待抢占
Pods中最大优先级最小的节点; - 再次选择待抢占
Pods优先级加和最小的节点; - 接下来选择待抢占
Pods数目最小的节点; - 最后选择拥有最晚启动
Pod的节点;
- 优先选择打破
通过过滤之后,会选出一个最合适的节点。对这个节点上待抢占的Pod进行delete,完成抢占过程。